
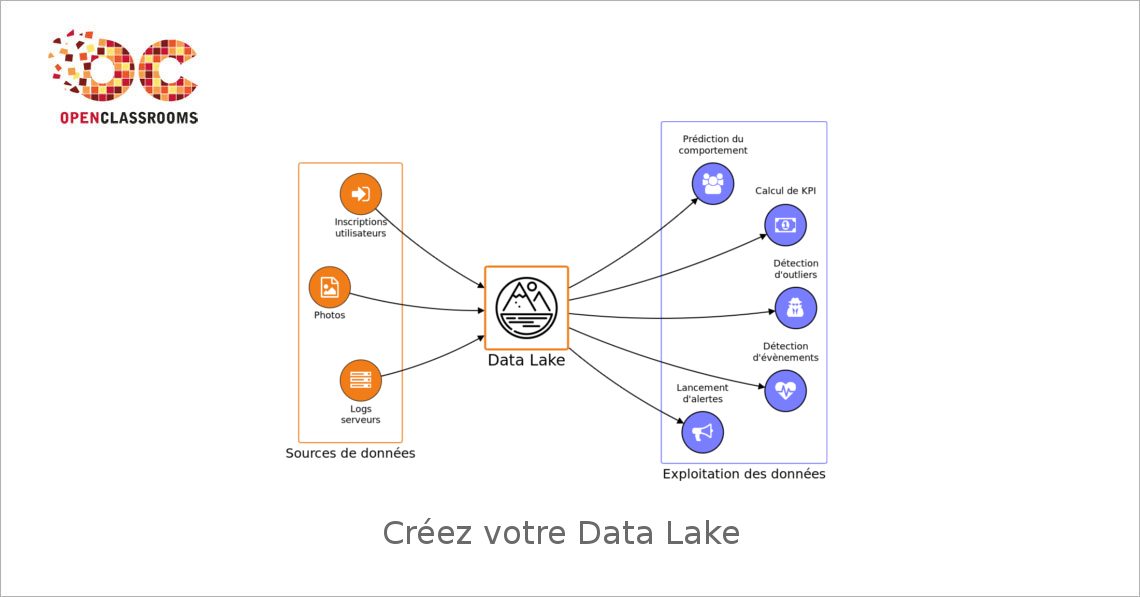
Lors de la conception d’une architecture Big Data, la première question concerne le stockage pur et simple des données brutes.
Où stocker les données ? Selon quel format ? Selon quelle hiérarchie ? Les solutions choisies doivent répondre à des impératifs de passage à l’échelle puisque la quantité de données à stocker va toujours croissant. Mais il ne s’agit pas pour autant d’archivage car il faut établir un accès aisé aux données pour permettre leur exploitation par des applications tierces.
Dans ce cours, vous apprendrez à concevoir un Data Lake : il s’agit d’un dépôt de données brutes accessible en lecture seule qui doit être la source de données de référence utilisée par les autres applications de traitement de données. C’est donc un composant fondamental de toute architecture Big Data !
Vous trouviez le stockage de données boring ? Vous allez changer d’avis !


Intervenants
Régis Behmo
Expert en machine learning, développeur fullstack, grimpeur invétéré et gros, très gros amateur de nouilles chinoises.Durée
Début le 11 Septembre 2017
Prérequis
Programmation : Connaissances en programmation objet (Java, Scala, Python, Ruby, C++ ou autre) et en structures de données.
Ingénierie informatique :
– Solides connaissances de l’environnement Unix.
– Gestion de la mémoire et des transferts de données.
– Connaissances réseau élémentaires.Charge de travail
8 heures au total
Coût
Gratuit
Certification
Vous devez compléter tous les exercices du cours et obtenir une note finale d’au moins 70% pour obtenir votre certification !
Un compte OpenClassrooms Premium Solo (20€ / mois) est nécessaire pour valider votre certification.
Déroulement
Chaque cours est composé d’une ou plusieurs parties et peut comporter du texte, des images (schéma, illustration) et des vidéos. Les vidéos des cours durent 10 minutes maximum, avec une moyenne de 3-4 minutes. Elles sont visualisables à tout moment sur OpenClassrooms et téléchargeables en haute définition.
Chaque partie d’un cours certifiant est ponctuée d’exercices de 2 types :
– des quiz corrigés automatiquement
– des devoirs libres (exemple : créer un site web avec des consignes précises).Ces devoirs sont évalués par les pairs. Chaque devoir est corrigé 3 fois par 3 autres élèves, dans un processus en double aveugle, selon un barème fixé par le professeur. La note finale est la moyenne des 3 notes reçues sur le devoir.
Si vous rencontrez des difficultés, pas de panique ! Vous pouvez à tout moment obtenir de l’aide sur les forums.
Programme
Partie 1 – Stockez vos données de manière distribuée avec HDFS
1. Identifiez les besoins de votre data lake
2. Découvrez le système de fichiers distribué HDFS
3. Mettez les mains dans le cambouis avec HDFS
4. Déployez HDFS en production et passez à l’échelle
Quiz : Devenez incollables sur l’administration d’un cluster HDFSPartie 2 – Sérialisez vos données avec Avro
1. Créez vos premiers schémas de données avec Avro
2. Faites évoluer vos schémas de données
3. Réalisez des analyses sur votre master dataset
Activité : Mangez des nouilles !Plateforme
OpenClassrooms
Une technologie issue du projet Open Source CLAIRE (Community Learning through Adaptive and Interactive multichannel Resources for Education) développé conjointement par OpenClassrooms (ex : Simple IT / Site du zéro), le laboratoire LIRIS (équipe Silex), et INRIA Grenoble (équipe WAM)









